Mastering Oracle SQL: Limit Queries, Create Tables & More!
Struggling with slow queries and inefficient data retrieval in your Oracle SQL database? Mastering the art of limiting queries is paramount for achieving optimal performance and creating seamless pagination experiences. This deep dive explores the power of the Oracle SQL limit function, specifically focusing on `rownum`, `row_number()`, and `fetch first`, equipping you with the knowledge to transform your database interactions.
Imagine a scenario where you need to display data in manageable chunks, like on a webpage with multiple pages. Without effective query limiting, you might be fetching the entire dataset, only to display a small portion. This is not only wasteful in terms of resources but also significantly impacts the responsiveness of your application. Oracle SQL provides several powerful tools to address this challenge, allowing you to retrieve precisely the data you need, when you need it.
| Feature | Description | Use Case | Syntax Example |
|---|---|---|---|
| `ROWNUM` | Assigns a sequential number to each row in the result set based on the order they are retrieved. It's crucial to apply filtering conditions carefully, as `ROWNUM` is assigned before the `WHERE` clause is fully processed. | Retrieving the first N rows of a query; implementing basic pagination. | `SELECT FROM (SELECT ROWNUM as rn, col1, col2 FROM table_name) WHERE rn <= 10;` |
| `ROW_NUMBER()` | A window function that assigns a unique sequential integer to each row within a partition of a result set. Unlike `ROWNUM`, `ROW_NUMBER()` is calculated after the `WHERE` clause and `ORDER BY` clause are applied, providing more predictable results. | Implementing more sophisticated pagination with sorting; identifying top N records based on a specific criteria. | `SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1 DESC) as rn FROM table_name WHERE condition = 'value';` |
| `FETCH FIRST` | A standard SQL feature that provides a cleaner and more intuitive syntax for limiting the number of rows returned. It directly specifies the number of rows to fetch and can be combined with `ORDER BY` for precise control over the result set. | Modern standard approach for limiting query results; preferred method for new development. | `SELECT col1, col2 FROM table_name ORDER BY col1 ASC FETCH FIRST 5 ROWS ONLY;` |
| Best Practices | Ensure you have proper indexes on the columns used in your WHERE and ORDER BY clauses, this dramatically increases query performance. | Optimization and ensuring efficient query running and retrieval of data | Always check your explain plan. |
Let's delve deeper into each of these techniques. `ROWNUM`, while being a classic Oracle feature, requires careful handling. It's essentially a pseudo-column that assigns a number to each row as it's being retrieved. The key thing to remember is that `ROWNUM` is assigned before the `WHERE` clause is fully executed. This can lead to unexpected results if you're not careful. For instance, if you try to retrieve rows where `ROWNUM > 1`, you'll likely get no results because the first row will be assigned `ROWNUM = 1`, and the condition `ROWNUM > 1` will immediately fail, preventing any subsequent rows from being considered.
To effectively use `ROWNUM` for limiting queries, you typically need to use a subquery. The subquery first selects the rows you want, and then the outer query assigns the `ROWNUM` and applies the limiting condition. Consider this example:
`SELECT FROM (SELECT ROWNUM as rn, col1, col2 FROM table_name WHERE condition = 'value') WHERE rn <= 10;`
In this example, the inner query selects all rows from `table_name` that satisfy the specified `condition`. The outer query then assigns a `ROWNUM` to each row in this result set and filters out the rows where `rn` (the assigned `ROWNUM`) is greater than 10. This effectively retrieves the first 10 rows that satisfy the condition.
`ROW_NUMBER()`, on the other hand, is a window function, which means it operates on a set of rows (a "window") related to the current row. Unlike `ROWNUM`, `ROW_NUMBER()` is calculated after the `WHERE` clause and `ORDER BY` clause are applied. This makes it much more predictable and easier to use for implementing pagination and ranking.
Here's how you can use `ROW_NUMBER()` to retrieve a specific page of results:
`SELECT col1, col2 FROM (SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1 DESC) as rn FROM table_name WHERE condition = 'value') WHERE rn BETWEEN 11 AND 20;`
In this example, the inner query selects rows from `table_name` that satisfy the `condition`, orders them by `col1` in descending order, and then assigns a unique `ROW_NUMBER()` to each row based on this ordering. The outer query then filters the result set to retrieve only the rows where `rn` is between 11 and 20. This effectively retrieves the second page of results, assuming each page contains 10 rows.
The `ORDER BY` clause within the `OVER()` clause is crucial because it determines the order in which the `ROW_NUMBER()` is assigned. Without an `ORDER BY` clause, the order of the rows is undefined, and the `ROW_NUMBER()` assignment will be arbitrary.
`FETCH FIRST` is a more modern and standardized approach to limiting query results. It's part of the SQL standard and provides a cleaner and more intuitive syntax. It directly specifies the number of rows to fetch and can be combined with `ORDER BY` for precise control over the result set.
Here's a simple example of using `FETCH FIRST`:
`SELECT col1, col2 FROM table_name ORDER BY col1 ASC FETCH FIRST 5 ROWS ONLY;`
This query selects `col1` and `col2` from `table_name`, orders the results by `col1` in ascending order, and then retrieves only the first 5 rows. The `ONLY` keyword is optional but improves readability.
`FETCH FIRST` also supports specifying a percentage of rows to fetch:
`SELECT col1, col2 FROM table_name FETCH FIRST 10 PERCENT ROWS ONLY;`
This query retrieves the first 10 percent of the rows in `table_name`. The percentage is calculated based on the total number of rows in the table before any filtering conditions are applied. If you need to apply a `WHERE` clause before calculating the percentage, you'll need to use a subquery.
One of the most critical aspects of database performance is the proper use of indexes. An index is a data structure that improves the speed of data retrieval operations on a database table. Think of it like an index in a book it allows you to quickly locate specific information without having to read the entire book.
In the context of Oracle SQL queries, indexes can significantly speed up queries that involve `WHERE` clauses, `ORDER BY` clauses, and `JOIN` operations. When you have an index on a column that is used in a `WHERE` clause, Oracle can use the index to quickly locate the rows that satisfy the condition, instead of having to scan the entire table.
Similarly, if you have an index on a column that is used in an `ORDER BY` clause, Oracle can use the index to quickly retrieve the rows in the desired order, without having to perform a separate sorting operation.
However, it's important to note that indexes come with a cost. They require storage space and can slow down data modification operations (i.e., `INSERT`, `UPDATE`, and `DELETE` statements) because the index also needs to be updated whenever the data in the table changes. Therefore, it's crucial to carefully consider which columns to index and to avoid creating unnecessary indexes.
Here are some general guidelines for creating indexes:
- Index columns that are frequently used in `WHERE` clauses, especially columns that are used in equality comparisons (`=`) or range comparisons (`<`, `>`, `<=`, `>=`).
- Index columns that are used in `ORDER BY` clauses, especially if the table is large and the sorting operation is slow.
- Index columns that are used in `JOIN` operations, especially if the tables being joined are large.
- Consider creating composite indexes (i.e., indexes on multiple columns) if you frequently query the table using multiple columns in the `WHERE` clause or `ORDER BY` clause.
- Avoid indexing columns that have low cardinality (i.e., columns that have very few distinct values), as the index may not provide much benefit.
- Monitor the performance of your queries and indexes regularly and adjust the indexes as needed.
In addition to limiting queries and using indexes, there are several other best practices that can help you optimize your database design and improve performance.
- Choose the right data types: Selecting the appropriate data types for your columns can significantly impact storage space and performance. For example, if you're storing integers, use `NUMBER` with the appropriate precision and scale. If you're storing strings, use `VARCHAR2` with the appropriate maximum length. Avoid using `CLOB` or `BLOB` data types unless absolutely necessary, as they can be more resource-intensive.
- Normalize your database schema: Normalization is the process of organizing your database schema to reduce redundancy and improve data integrity. A well-normalized database schema can make it easier to query and maintain your data.
- Use partitioning: Partitioning is the process of dividing a table into smaller, more manageable pieces. This can improve query performance, especially for large tables. Oracle supports several types of partitioning, including range partitioning, list partitioning, and hash partitioning.
- Optimize your SQL queries: Writing efficient SQL queries is essential for good database performance. Use the `EXPLAIN PLAN` statement to analyze the execution plan of your queries and identify potential bottlenecks. Consider rewriting your queries to use more efficient algorithms or to take advantage of indexes.
- Use connection pooling: Connection pooling is a technique that reuses database connections instead of creating a new connection for each request. This can significantly reduce the overhead of establishing and closing database connections, especially in high-volume environments.
- Monitor your database performance: Regularly monitor your database performance using tools like Oracle Enterprise Manager or Statspack. Identify slow-running queries, high resource utilization, and other potential problems. Take corrective action as needed to maintain optimal performance.
Creating tables is fundamental to any database system. In Oracle SQL, the `CREATE TABLE` statement is used to define the structure of a new table, including its columns, data types, and constraints. Let's explore the process of creating a table in Oracle SQL with a detailed guide.
The basic syntax for creating a table in Oracle SQL is as follows:
`CREATE TABLE table_name ( column1 data_type [constraint], column2 data_type [constraint], ... );`
Let's break down each part of this statement:
- `CREATE TABLE table_name`: This specifies that you are creating a new table with the given name. The table name must be unique within the schema.
- `( column1 data_type [constraint], ... )`: This defines the columns of the table, along with their data types and any constraints that should be applied.
- `column1 data_type`: This specifies the name and data type of a column. The column name must be unique within the table. The data type determines the type of data that can be stored in the column (e.g., `NUMBER`, `VARCHAR2`, `DATE`).
- `[constraint]`: This is an optional clause that specifies a constraint to be applied to the column. Constraints enforce rules on the data that can be stored in the column, such as uniqueness, non-null values, or referential integrity.
Here's an example of creating a simple table called `employees`:
`CREATE TABLE employees ( employee_id NUMBER(6) PRIMARY KEY, first_name VARCHAR2(20), last_name VARCHAR2(25) NOT NULL, email VARCHAR2(25) UNIQUE, phone_number VARCHAR2(20), hire_date DATE NOT NULL, job_id VARCHAR2(10) NOT NULL, salary NUMBER(8,2), commission_pct NUMBER(2,2), manager_id NUMBER(6), department_id NUMBER(4) );`
In this example, the `employees` table has several columns, including `employee_id`, `first_name`, `last_name`, `email`, `phone_number`, `hire_date`, `job_id`, `salary`, `commission_pct`, `manager_id`, and `department_id`. Each column is defined with a specific data type and, in some cases, a constraint. For example, the `employee_id` column is defined as `NUMBER(6) PRIMARY KEY`, which means that it can store integers up to 6 digits long and that it is the primary key of the table (i.e., it must be unique and not null). The `last_name` column is defined as `VARCHAR2(25) NOT NULL`, which means that it can store strings up to 25 characters long and that it cannot be null. The `email` column is defined as `VARCHAR2(25) UNIQUE`, which means that it can store strings up to 25 characters long and that all values in this column must be unique.
Oracle SQL supports a wide variety of data types, including:
- `NUMBER(p,s)`: Stores numeric data with a precision of `p` digits and a scale of `s` digits. The precision specifies the total number of digits that can be stored, and the scale specifies the number of digits to the right of the decimal point.
- `VARCHAR2(size)`: Stores variable-length character strings up to the specified `size` in bytes.
- `CHAR(size)`: Stores fixed-length character strings of the specified `size` in bytes.
- `DATE`: Stores date and time values.
- `TIMESTAMP`: Stores date and time values with fractional seconds.
- `CLOB`: Stores large character strings (up to 4 GB).
- `BLOB`: Stores large binary objects (up to 4 GB).
Constraints are rules that enforce data integrity and consistency. Oracle SQL supports several types of constraints, including:
- `PRIMARY KEY`: Specifies that a column or set of columns is the primary key of the table. A primary key must be unique and not null.
- `FOREIGN KEY`: Specifies that a column or set of columns is a foreign key that references another table. A foreign key establishes a relationship between two tables.
- `UNIQUE`: Specifies that all values in a column must be unique.
- `NOT NULL`: Specifies that a column cannot contain null values.
- `CHECK`: Specifies a condition that must be satisfied by all values in a column.
Here's an example of creating a table with a foreign key constraint:
`CREATE TABLE departments ( department_id NUMBER(4) PRIMARY KEY, department_name VARCHAR2(30) NOT NULL, manager_id NUMBER(6), location_id NUMBER(4) ); CREATE TABLE employees ( employee_id NUMBER(6) PRIMARY KEY, first_name VARCHAR2(20), last_name VARCHAR2(25) NOT NULL, email VARCHAR2(25) UNIQUE, phone_number VARCHAR2(20), hire_date DATE NOT NULL, job_id VARCHAR2(10) NOT NULL, salary NUMBER(8,2), commission_pct NUMBER(2,2), manager_id NUMBER(6), department_id NUMBER(4), FOREIGN KEY (department_id) REFERENCES departments(department_id) );`
In this example, the `employees` table has a foreign key constraint on the `department_id` column, which references the `department_id` column in the `departments` table. This ensures that the `department_id` value in the `employees` table is a valid `department_id` value in the `departments` table.
Beyond the basic syntax, there are several best practices to keep in mind when creating tables in Oracle SQL. Proper database design and data types are crucial to optimize your database design.
- Use meaningful names: Choose descriptive and consistent names for your tables and columns. This will make your database schema easier to understand and maintain.
- Document your schema: Add comments to your `CREATE TABLE` statements to explain the purpose of each table and column. This will help others understand your schema and make it easier to maintain.
- Consider using sequences: If you need to generate unique, sequential numbers for your primary keys, consider using sequences. Sequences are Oracle database objects that generate unique numbers.
- Use constraints wisely: Constraints are a powerful tool for enforcing data integrity, but they can also impact performance. Use constraints judiciously and consider the performance implications of each constraint.
- Test your schema: Thoroughly test your database schema after creating it to ensure that it meets your requirements and that the constraints are working as expected.
Traditional factual question answering (QA), exemplified by questions like "\u201cwho is the president of the United States?\u201d", differs significantly from more complex QA systems. These systems require deeper comprehension of text and knowledge bases.
The Stanford Question Answering Dataset (SQuAD 1.1) contains over 100,000 questions designed for machine comprehension of text, pushing the boundaries of what QA systems can achieve.
Current research focuses on learning question answering over QA corpora and knowledge bases, aiming to build systems that can understand the nuances of language and reason about complex relationships. One approach involves constructing QA systems on open-domain knowledge bases. Existing rule-based QA systems often struggle to understand variations in question phrasing, while keyword-based methods lack true comprehension. A promising approach involves using models trained on massive knowledge bases and QA datasets.
Regularization techniques leverage the duality between question answering (QA) and question generation (QG). Considering the conditional probability p(a|q;\u03b8qa) and discrepancies in QA model outputs, one can sample answer sentences a' given a question q to derive p(a|q;\u03b8qa). Implementational details often involve distinct embedding matrices for question words and answer words to capture specific semantic nuances.
In 2019, key research directions in intelligent question answering focused on approaches that leverage large datasets and sophisticated models. As of mid-2020, the field continues to evolve, with researchers exploring new techniques for improving question understanding, knowledge base integration, and answer generation.
Zhihu, a prominent Chinese Q&A platform, offers a unique opportunity for brands to share valuable information and expertise with its users. Launched in 2010, Zhihu has become a leading platform for asking and answering questions on a wide range of topics, including technology, science, entertainment, and current events.
Zhihu's position as a content producer and sharing platform provides brands a unique position. Zhihu is the largest Chinese Q&A platform and gives advantages for both netizens and companies. Zhihu marketing in China can be a good marketing strategy.
Zhihu provides answers through focusing on topics, focusing on questions, focusing on users. Through information classification, Zhihu enables people to establish connections.
Users can follow influencers and receive notifications about their posts, fostering a dynamic and participatory environment. Zhihu's mission is to enable people to share knowledge, experience, and insights better and to find their own answers.

eTOC What is Zhihu? A complete guide of the Chinese Q&A platform
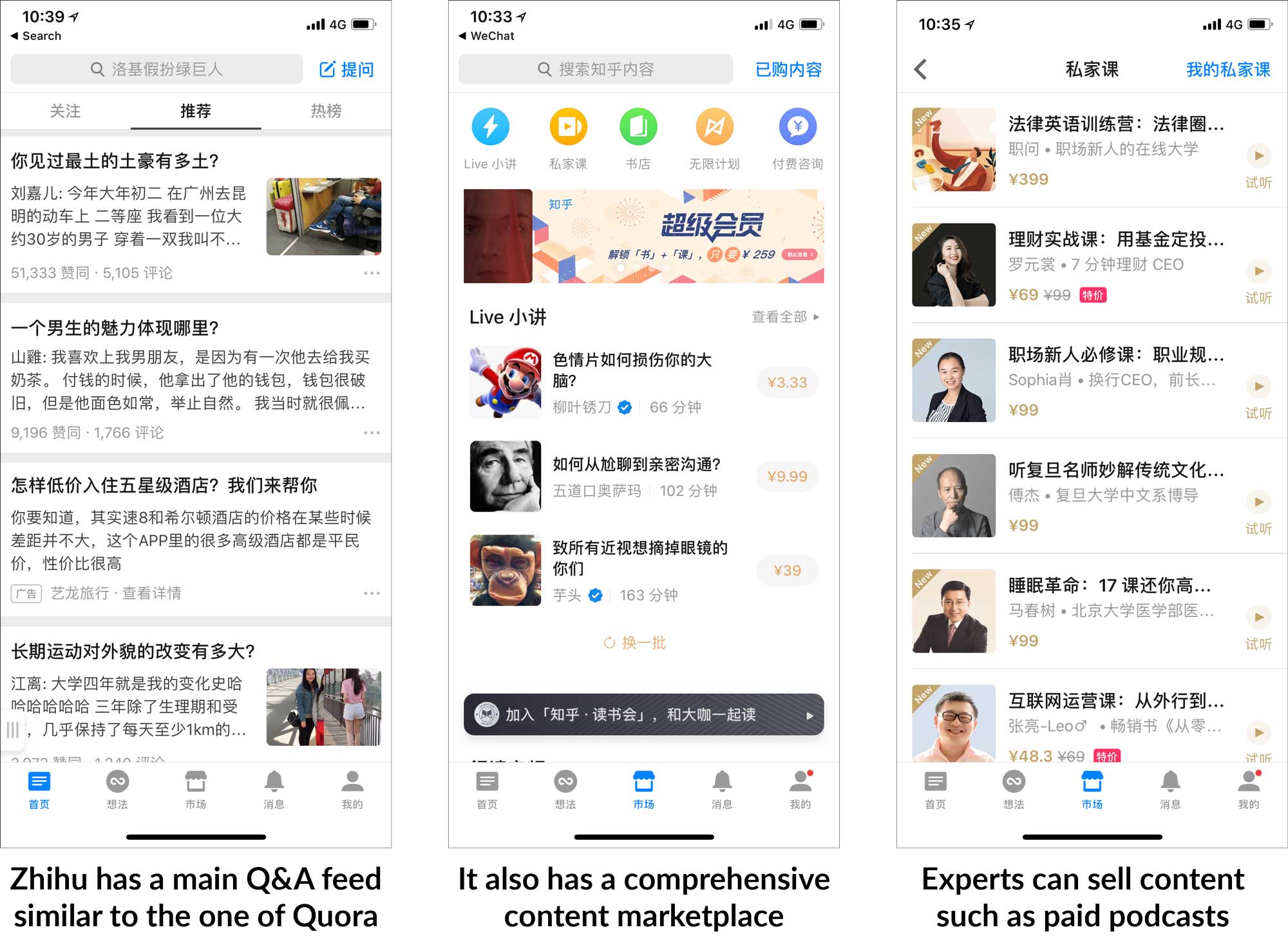
Zhihu China’s Largest Q&A Platform is a Content Marketer's Dream

How To Use Zhihu for Chinese B2B Marketing (2019) Nanjing Marketing Group
